Resource vs. Source
Adam Mathes
Knowledge Representation and Formal Ontology Final Project
Graduation School of Library and Information Science
UIUC
April 2005
What is a resource?
- RDF is a "Resource Description Framework"
- URL is a "Uniform Resource Locator"
- URI is a "Uniform Resource Identifier"
But what is a resource?
What is a resource? (TBL's answer)
T. Berners-Lee
RFC 2396 - Uniform Resource Identifiers (URI): Generic Syntax
"A resource can be anything that has identity. Familiar examples include an electronic document, an image, a service (e.g., "today's weather report for Los Angeles"), and a collection of other resources. Not all resources are network "retrievable"; e.g., human beings, corporations, and bound books in a library can also be considered resources."
What is a resource? (TBL's answer part 2)
"The resource is the conceptual mapping to an entity or set of entities, not necessarily the entity which corresponds to that mapping at any particular instance in time. Thus, a resource can remain constant even when its content---the entities to which it currently corresponds---changes over time, provided that the conceptual mapping is not changed in the process."
But seriously, what is a resource?
W3C semantic web activity basically dodges this - resources are things that can be identified by a URI. "Things that have identity" doesn't tell us much.
But I don't want to talk about real life people that are identified by a URI/URL string, although perhaps what we discover here will apply or be related to those discussions as well.
Limiting this discussion to web resources - pages, sites, documents, web applications, web services.
Static Pages are (almost) Easy
Simplest case is a static page of HTML
Properties:
- Same "informational content"
- regardless of user
- regardless of time of access (static by definition)
- regardless of changes in the outside world (mostly)
The world is not static
But many of the web resources we care about are not static pages
- Your LEEP homepage
- My Yahoo
- New York Times
- Citeseer entry for Towards a semantics for XML markup
Is there such a thing as static?
Even static pages are often not really static
- "small" edits over time
- URL changes - but same document (new server software, etc)
- dynamic content like advertising, time of day of access, etc
- XML document identity is hard (see Renear, Dubin, for more problems)
How current web applications work
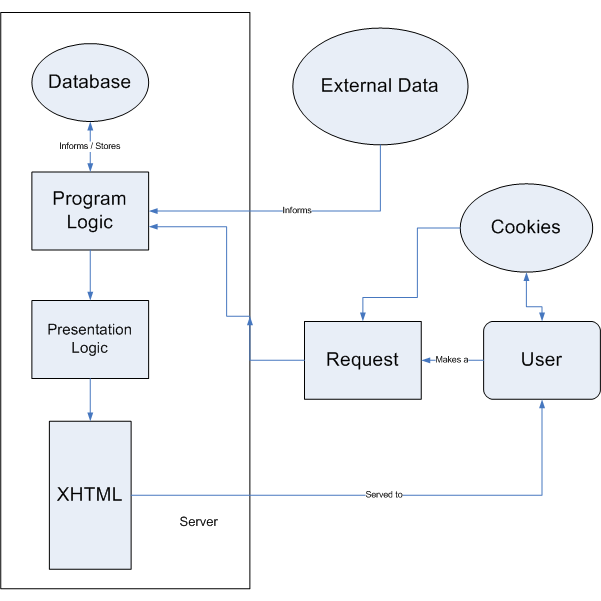
Technology to higher level abstraction
Moving away from current technology and implementation to what is fundamentally going on
Can we create a reasonable ontology for what's going on here?
Some things to distinguish
Resource from an "instance" of that resource
Instance is an access of a resource in a particular context
What is necessary to include in a context? (What is a context?)
Distinguish resources from the "sources" that comprise and inform that resource
Some things to consider about / worry about
Mixed and often contradictory or ambiguous vocabulary in this domain
- Pages, documents, resources, URL, URI, services, sites, application endpoint
What level of abstraction are we working on?
- FRBR connections or disconnects
- (I kind of ignore this right now)
Questions to consider
What kind of question do we want to be able to answer?
- What sources inform / effect a resource?
- Has a resource changed? What does that mean?
- Are instance A and instance B the same?
- Are instance A and instance B instances of the same resource?
- Is a resource static or dynamic?
Although, it may be useful to ontologize regardless of intended use just for a better understanding of this domain. (This as academia, after all.)
Some first attempts at an ontology
(Will indubitably have serious problems)
Resources are...
...things with identity?
- has at least one URI / URL, maybe more
- URI(r) = http://www.leep.lis.uiuc.edu
- URL(r) = { http://www.leep.lis.uiuc.edu, http://leep.lis.uiuc.edu }
...the higher level abstract thing that that a set of instances belongs to
...the conceptual mapping of a "concept" to a set of other entities (accesses, instances?)
...a resource may just have to a primitive abstract thing (like work)
Mappings, Context
corresponding to "program / display logic" part of original diagram
can we distinguish a resource from this mapping? (I think so)
- a resource has a mapping / function that takes contexts and returns instances
- this corresponds to an "access" of that resource
- r is a resource, c is a context
- i is an instance of resource r in context c
- ResourceAccess(r, c) = i
Contexts
- Sources inform resources by being part of a context of access
- contexts are a set of assertions, might include
- time, date (seconds from epoch)
- the headlines of the New York Times (XML representation in an RSS feed)
- your identity (from cookies stored by browser)
- the geographic location of the computer accessing (from IP address)
- inventory information (from a database sitting next to the server)
- c is a context and x, y, and z are assertions
- c = {x, y, z}
Instances
Instances are also sets of assertions
These instances are dependent on:
- the resource
- the context (that set of assertions)
- the mapping function (this may also change?)
A Visual Description
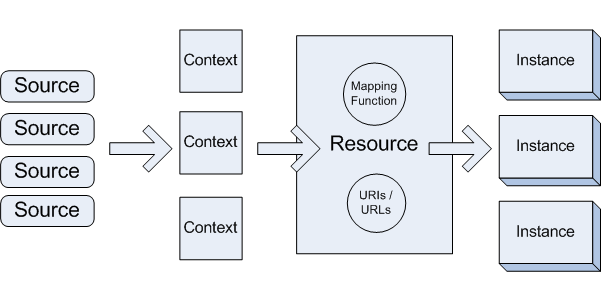
How do we determine identity of a resource?
Do resources intrinsically have identities?
If the sources change, we still have the same resource, says TBL (and me)
What if the mapping function changes?
- slightly cosmetic?
- removes some information?
- same output, but different program? (efficiency changes)
- redirects all users to something inappropriate?
Honestly, I'm not sure.
Is a resource dynamic or static?
r is a static resource iff
∀c ResourceAccess(r,c) = i
- but... what about temporary server outages?
- what about network problems?
- what about changes of assertions after transmission from server?
(Google toolbar AutoLink, Greasemonky firefox extension)
May need the concept of a valid domain of contexts for a resource
Source / resource relation
Does a source inform / effect a resource?
Does a resource depend on a source?
For resource r and source s
If ∃ c1 and c2 s.t. c1 and c2 are within the domain of r
and c1, c2 differ only in s value (or presence)
ResourceAccess(r, c1) = i1
ResourceAccess(r, c2) = i2
s.t i1 and i2 are not equal, then r depends on s / s informs r.
Informs(s, r)
Depends(r, s)
(Or maybe simplified to ∃ c s.t. s belongs to c and c is in the domain of r)
What we need of FOL
- literals (for assertions)
- two-input predicate functions
- sets and the notion of set equality
- ...maybe more?
Problems
- This idea of contexts seems... difficult. Should I avoid this ontological commitment?
- Is the idea of an instance / access necessary?
- Do we need sets?
- Can resources really exist independent of access?
- Does any of this force us to reevaluate FRBR?
- Does it strengthen our notion that FRBR says something about the universe of knowledge between printed books?
- probably lots more
But what about...?
Questions